Introduction
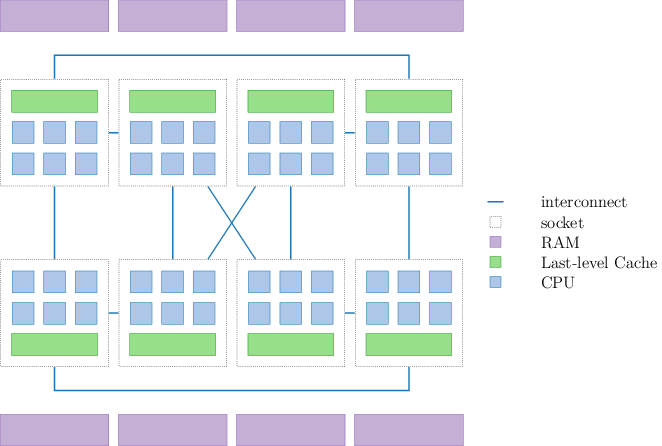
Modern NUMA multicore machines exhibit complex latency and throughput characteristics, making it hard to allocate memory optimally for a given program’s access patterns. However, good placement of and access to program data is crucial for application performance, and, if not carefully done, can significantly impact scalability. Although there is research for how to adapt software for concrete characteristics of such machines, many programmers struggle to apply these to their applications.
It is unclear which NUMA optimization to apply in which setting. For example, some programs have good access locality and it is worth co-locating code with the data it is accessing. Other programs exhibit random accesses and it is best to spread code and data across the entire machine to maximize total bandwidth to memory. The situation becomes even more complex as we consider large page sizes (where the data on a large page must be co-located physically), non-cache-coherent memory with different characteristics, or heterogeneous and specialized cores. With rapidly evolving and diversifying hardware, programmers must repeatedly make manual changes to their software to keep up with new hardware performance properties.
One solution to achieve better data placement and faster data access is to rely on automatic online monitoring of program performance to decide how to migrate data. However, program’s semantics then have to be guessed in retrospect from a narrow set of available information (i.e. from data based on sampling using performance counters). Such approaches are also limited to a relatively small number of optimizations. For example, it is hard to incrementally activate large pages or enable the use of DMA hardware for data copies dynamically.
We present Shoal, a system that abstracts memory access and provides a rich programming interface that accepts hints on memory access patterns at runtime. These hints can either be manually written or automatically derived from high-level descriptions of parallel programs. Shoal includes a machine-aware runtime that selects optimal implementations for this memory abstraction dynamically based on the hints and a concrete combination of machine and workload. If available, Shoal is able to exploit not only NUMA properties but also hardware features such as large and huge pages as well as DMA copy engines.
Our contributions are as follows: Firstly, we provide higher-level memory abstractions to allow Shoal to change memory allocation and access at runtime. In our prototype, we provide an array-like abstraction, designed for use in C/C++ code. Secondly, we introduce techniques for automatically selecting among several highly tuned array implementations using access patterns and machine characteristics. Finally, we modified Green-Marl, a graph analytics language, to show how Shoal can extract access patterns automatically from high-level descriptions. We demonstrate significant performance benefits when applying these techniques to Green-Marl when using Shoal for unmodified Green-Marl programs.
Evaluation
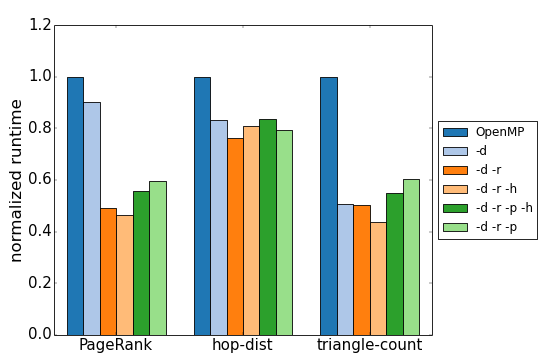
First we show the scalability of Green-Marl when using Shoal compared to the original OpenMP version. We modified the Green-Marl compiler to extract access patterns automatically. Green-Marl programs are unmodified.
Shoal arrays have various highly-tuned implementations. The following gives an overview of their performance for several Green-Marl programs.
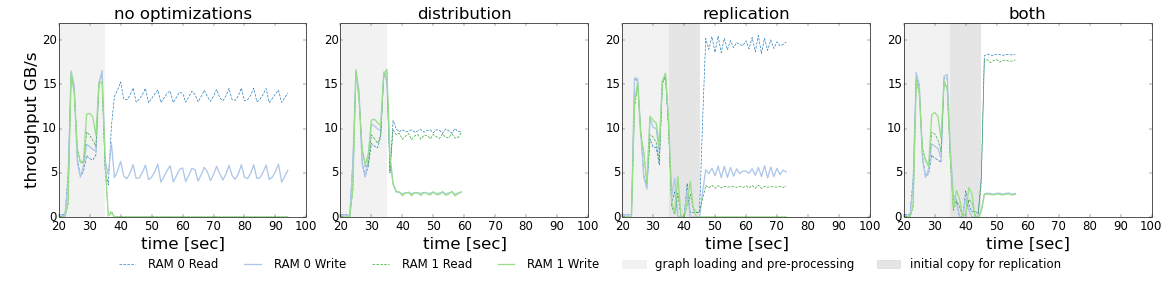
Shoal's Green-Marl is faster than the unmodified original because Shoal chooses array implementations such that memory accesses are distributed equally on various memory controllers and traffic on interconnects is reduces while accesses are kept local as much as possible.
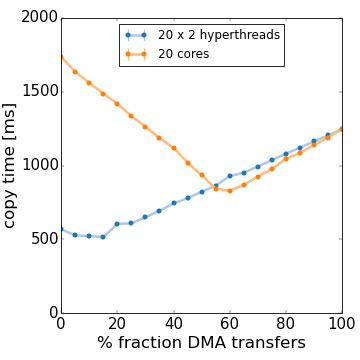
Abstracting memory accesses as we do with Shoal has further benefits. High-level operations on arrays, for example, allow to advanced hardware features otherwise often unused due to their diversity and complexity to program.
Currently, Shoal supports use of large- and hugepages as well as DMA engines, if available in the machine.
Publications
Shoal: smart allocation and replication of memory for parallel programsStefan Kaestle, Reto Achermann, Timothy Roscoe, Tim Harris
Proceedings of the 2015 USENIX conference on Annual Technical Conference, Santa Clara, CA, USA, July 2015.
paper slides
Presentations and Posters
USENIX ATC'15: presentation video
Source-code
Shoal is available
from github.
To install, please follow the instructions for
Shoal and Stremacluster
as well as Green Marl
on github.


